


I’ve been playing around with generative adversarial networks this week. In particular, using image-to-image translation to see what we can create using images of circuit boards.
I’ve noticed before that circuit boards mildly resemble aerial geospatial images. What kinds of cities could we build with them?
Model Overview
GANs
GAN stands for Generative Adversarial Network: generative, because we are using it to generate data; adversarial, because it comprises of two competing networks; and network, because we are describing a neural network architecture.
Essentially, you have two models competing: a generator that generates fake images, and a discriminator that judges whether an image is fake or real.
First, we generate a bunch of fake images using the generator. Then, we take these fake images to the discriminator, which classifies images as fake or real. Using the information on how the discriminator determined which images are fake, we take that back to the generator so we can generate better fake images. We repeat this process, taking turns training the generator, then the discriminator, until the discriminator can no longer tell which images are real or fake (generated).
Pix2Pix
The pix2pix model uses conditional adversarial networks (aka cGANs, conditional GANs) trained to map input to output images, where the output is a “translation” of the input. For image-to-image translation, instead of simply generating realistic images, we add the condition that the generated image is a translation of an input image. To train cGANs, we use pairs of images, one as an input and one as the translated output.
For example, if we train pairs of black-and-white images (input) alongside the color image (translation), we then have a model that can generate color photos given a black-and-white photo. If we train pairs of day (input) and night (translation) images of the same location, we have a model that can generate night photos from day photos.
CycleGAN
A related model architecture is CycleGAN (original CycleGAN paper), which builds off of the pix2pix architecture, but allows you to train the model without having explicit pairings. For example, we can have one dataset of day images, and one dataset of night images; it’s not necessary to have a specific pairing of a day and night image of the same location. To train CycleGAN, we can use unpaired training data. (CycleGAN is not used here but I hope to explore it more this week!)
The pretrained models I used for these explorations are from a PyTorch implementation of pix2pix that can be found on Github.
Results
In the results below, on the left is the circuit board image input, and on the right is the generated translation.
Circuit Boards to Buildings
For these, I used the facades_label2photo pretrained model, originally trained on paired images like this:
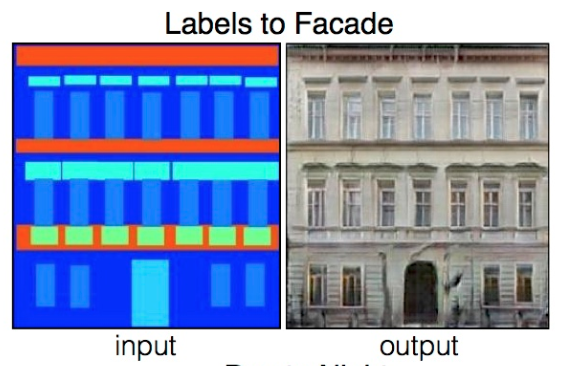
Labels to Facade


















Circuits to Maps
For these, I used the sat2map pretrained model, originally trained on paired of satellite aerial images (input) and Google maps (translation).




Circuits to Satellite Images
For these, I used the map2sat pretrained model, originally trained on paired of Google maps images (input) and satellite aerial images (translation).







