Have you ever wondered what a Gyarados would look like as a fire type? Or grass type, or electric type?
For my last project at the Recurse Center, I trained CycleGAN, an image-to-image translation model, on images of Pokémon of different types.


Model Overview
CycleGAN is an image-to-image translation model that allows us to “translate” from one set of images to another. For more on CycleGAN, see previous blog posts on image-to-image translation with CycleGAN and pix2pix.
The open-source implementation used to train and generate these images of Pokémon uses PyTorch and can be found on Github. For this project, I trained the model to translate between sets of Pokémon images of different types, e.g. translating images of water types to fire types.
Training Data
I found the original dataset of Pokémon images and their types on Kaggle, containing Generations 1-7. I wrote a script to sort the Pokémon images by their primary type.
The resulting dataset, as well as the script, can both be found on my Github.
Results
For each pair of images, on the left is the original image of the Pokemon, and on the right is the type-translated version. (Results are best viewed if you turn off f.lux, night shift, or any other display mode that changes the color of your screen.)
Water type -> other types
































Fire type -> other types




































Grass type -> other types



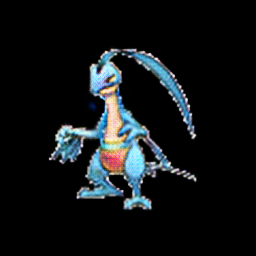








Electric type -> other types




Dragon type -> other types
















Dark type -> other types