Dogs!!! More dogs this week!!! Is it possible I picked this project because I was in the mood for dog pictures? Absolutely.
This week, I used the CycleGAN image-to-image translation model to translate between images of Samoyeds and Bernese mountain dogs, two of my favorite dogs. If you’re not familiar with these breeds, you’re in luck, because here are some dog pictures for your reference. (Such good dogs!!)

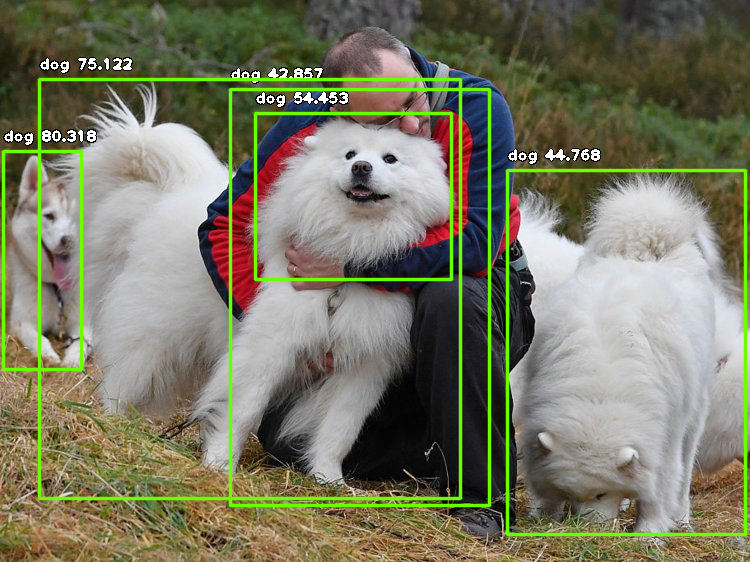
One very good Samoyed

Two very good Bernese mountain dogs
Model Overview
CycleGAN builds off of the pix2pix network, a conditional generative adversarial network (or cGAN) that can map paired input and output images. Unlike pix2pix, CycleGAN is able to train on unpaired sets of images. For more on pix2pix and CycleGAN, see my previous blog post here.
The CycleGAN implementation used to train and generate dog pictures uses PyTorch and can be found on Github here. (This repo also contains a pix2pix implementation, which I had used previously to generate circuit cities.)
A major strength of CycleGAN over pix2pix is that your datasets can be unpaired. For pix2pix, you may have to really dig, curate, or create your own dataset of 1-to-1 paired images. For example, if you wanted to translate daytime photos to nighttime photos with pix2pix, you would need a pair of daytime and nighttime photos of the same location. With CycleGan, you can just have a set of daytime photos of any location and a set of nighttime photos of any location and call it a day (no pun intended).
Another strength of CycleGAN over, say, neural style transfer, is that the translations can be localized. In the following examples, you’ll see that the translation applies only to the dog. Object recognition is implied, and the non-dog portions of the images are not really affected. With neural style transfer, you’re applying a style transformation to the entire image.
As an aside, I originally ran CycleGAN on a set of images of forests, and a set of images of forest paintings. While the results did turn out as expected, I realized this kind of task is really best suited for neural style transfer. (Which inspired me to implement it from scratch! See previous blog post on implementing neural style transfer from scratch in PyTorch.)
Training Data
To train the model, I used 218 images of Samoyeds and 218 images of Bernese mountain dogs from one of my favorite datasets currently on the internet: the Stanford Dogs Dataset. So many good dogs!! My heart!!
GPU training time took a couple of hours on an NVIDIA GeForce GTX 1080 Ti, and generating results only took a few minutes.
Results
In the following examples, on the left is the input, a real photo of a Samoyed. On the right is the CycleGAN output, a generated image translated from the input into a Bernese mountain dog.


















Notes
Note that, since this is a blog post and not a scientific paper, I’ve only included the more effective results in this post. For example, bernese2samoyed doesn’t look quite as good — it just looks like white-out was applied to the dog lol.


I would add that a major strength of cycleGAN is that the changes are applied locally, and not to the entire image. The network is able to identify the boundaries of dog and not-dog.
Another note is that this approach seems to work best when translating between inputs with similar shapes. In these results, mainly the coloring was transferred, and not so much the dog shape. I would posit that breeds that are similar in shape would yield more effective results, e.g. translating between golden and chocolate labs, or between tabby cats and tortoise shell cats.